

I've worked in labs where the inventory "system" was a binder in the office with handwritten entries that were not only usually out of date, but also took ages to find anything in. I also once watched a postdoc spend an entire afternoon searching four freezers across two floors for an antibody that, as it turned out, one of the PhD students had used up the week before and never mentioned. The postdoc's experiment, which had taken weeks to set up and get right, was ruined. The working relationship between said PostDoc and PhD student took several weeks to thaw after that incident - no pun intended.
Lab inventory management is one of those things that only gets attention when something goes wrong. The reagent that wasn't there when you needed it. Or the order that went through twice because nobody realized it had already been placed. But these visible disasters are just the tip of the iceberg.What doesn't get noticed is the steady accumulation of smaller losses: reagents expiring unnoticed, stock being reordered when there's plenty sitting in a freezer two rooms over, or the hours researchers wasted hunting for things. By the time anyone pays attention, those hidden costs have often been running into thousands of dollars a year. It's just not a line item on anybody's budget sheet, so it goes unnoticed or ignored for way too long.
It's not a glamorous problem to solve, either. And by the time a lab's inventory gets REALLY problematic - i.e. overflowing minus-80 freezers that nobody knows the contents of, shelves crammed with half-empty bottles of who-knows-what - the burden of work to go through everything and properly log what's stored in the various fridges, freezers, shelves, and cupboards of the lab is enormous. Nobody wants to take it on. Because everyone has their research projects to worry about. In research, there's just never a good time to drop everything for days or weeks to get your lab inventory in order.
But in the meantime, the chaos keeps mounting. And it puts a very real, significant drain on your lab's resources.
Here's the thing, though: with the right system and just a small amount of buy-in from your team, you can get your inventory management on the right track gradually, without too much pain and hassle. You don't have to drop everything and bring your research to a halt to do it.
This guide is about what actually goes wrong with lab inventory management and why the common fixes don't work. We'll also cover what a real solution looks like in practice, and (maybe most importantly) how you can make the transition gradually without disrupting your research.
The spreadsheet era (and why it needs to end)
Let's start with the tool that most labs default to: the shared spreadsheet. Google Sheets, Excel on a shared drive, maybe a fancy one with color coding and dropdown menus. Someone put real effort into building it. It probably looked great on day one.
The problem is that spreadsheets depend entirely on human discipline to stay accurate. Every person in the lab needs to update the sheet every time they take something, use something, move something, or receive something. In a busy research environment, that discipline lasts about two weeks. After that, some people update it, some people don't, and the data drifts further from reality with each passing day.
I've talked to lab managers who spend hours every month doing manual audits - walking through storage rooms with a clipboard, checking actual stock against what the spreadsheet says - just to keep the data roughly current. Think about that for a second. That's essentially a part-time job dedicated to keeping a spreadsheet from drifting too far from reality - and all of a sudden the “free” inventory management via a spreadsheet becomes rather expensive.
And spreadsheets have plenty of other problems. They don't reliably track who made changes or when. It's easy (and actually quite common) for someone to accidentally delete or overwrite information. Google Sheets does have a document history, technically, but have you ever actually tried to use it? It's not exactly human-friendly. Searching through a messy revision log to figure out when a specific change was made and by whom, while the rest of the team continues editing the document in real time; it’s a real time-sink and usually not worth the effort. You'll burn an hour and still come away unsure of what happened.
The core issue is that spreadsheets were never designed to be used as an inventory management system by a whole team of people. They also don't connect to your experiment records. They can't show you how a sample relates to other samples in your collection. They don't enforce any structure: one person enters "anti-CD3 antibody" and another enters "aCD3 Ab" and now you have the same reagent listed twice under different names. Try running a meaningful search or audit on data like that.
The reason labs stick with spreadsheets isn't that they work well. It's that they're free and familiar, and the alternatives have historically been either too expensive or too complicated to justify. That's been changing, but old habits are hard to break.
What a lab inventory management system actually does
A proper laboratory inventory system does what spreadsheets never could. You get structured, searchable records of what your lab has, where it's stored, who's been using it, and what for. And crucially, with the right system, you can also see how all of that connects to your actual research.
In practice, this means you set up inventory repositories that match how your lab actually organizes things. Your antibody collection needs to capture different metadata than your primer stocks - things like conjugate or host species. Primer stocks need different fields than your cell line bank. If you choose the right system, you define the categories and metadata that matter for each type of material. Storage locations get mapped out so you're not just tracking that something exists, you can see the specific building, room, freezer, shelf, and box position where it's sitting right now.
Tracking samples goes deeper than just knowing what you have on hand. Where did a sample come from? Who's handled it? What experiments has it been used in? If it's a derived cell line or an aliquot from a parent stock, what's the lineage? How are the samples related? In regulated environments this kind of traceability is a requirement, but honestly it's useful in any lab that wants to actually understand the history of their materials and improve the reproducibility of their results.
Tracking reagent usage is the other piece that changes things. Rather than guessing how much you have left based on the weight of the bottle, or relying on someone to check and report back, consumption gets logged as materials are used. After a few months you start to see patterns - which reagents your lab burns through, which ones barely get touched, and roughly when you'll need to reorder. That kind of data takes the guesswork out of purchasing, and most lab managers I've talked to say it was worth the switch for this alone.
Why standalone LIMS software often disappoints
At this point you might be thinking: "This is what LIMS software is for." And you'd be right. A Laboratory Information Management System is designed to handle exactly these kinds of tasks: sample management, inventory tracking, workflow automation, compliance documentation.
The trouble is that traditional LIMS systems were built for a different era. Many of them are rigid, overly complex, and require extensive configuration, vendor support, or dedicated IT staff to keep running. They were designed for large pharmaceutical companies and clinical labs with big budgets and full-time informatics teams or in-house software engineers. For a 15-person biotech startup or an academic research group, that kind of LIMS system is overkill in both complexity and cost.
Flexibility is the other issue that doesn't get talked about enough. Modern research is far more diverse and fluid than it was twenty years ago. The range of treatment modalities alone - from traditional small molecules to biologics, monoclonal antibodies, ADCs, cell and gene therapy, mRNA-based therapeutics, and beyond - means labs need systems that can adapt to very different workflows. And advances in technology keep expanding the number of assays and experimental approaches any given team might use. A LIMS that can't adjust to changing needs becomes a bottleneck rather than a tool. Most traditional LIMS were simply not built with that kind of flexibility in mind.
The whole inspiration behind building IGOR actually came from working at the bench as a lab scientist in a preclinical lab and having to use one of the market-leading LIMS platforms. The software cost an arm and a leg and was still so clunky and rigid that it caused more problems than it solved. It struggled with basic workflows and wasn't even flexible enough to let users correct simple instances of human error, like accidentally logging out the wrong sample. If your LIMS can't handle a mistake that takes two seconds to make, something has gone very wrong in the design.
But even among the newer cloud based LIMS platforms, there's a common problem: the LIMS handles inventory and sample management reasonably well, but it treats experiment documentation as an afterthought. You end up with a solid sample inventory management tool that doesn't connect meaningfully to the actual research documentation. Your LIMS knows what materials you have and where they are, but it doesn't know what experiments they were used in, what results they produced, or what protocols were followed. That context lives somewhere else - in a separate electronic lab notebook, in paper notebooks, on someone's external hard drive.
Which brings us to what I think is the most important insight about lab inventory management: it doesn't work well in isolation. Inventory management and experiment documentation feed into each other constantly, and separating them into different tools creates exactly the kind of fragmentation that makes lab data management so frustrating in the first place.
The case for putting your ELN and LIMS in the same platform
Think about what happens during a typical experiment. A researcher follows a protocol. They use specific reagents - particular lots, particular concentrations. Along the way they pull samples from the freezer, use reagents from various storage locations, maybe create new samples or aliquots. Then they write up what happened and what the data showed.
When your documentation and inventory live in different systems, the researcher writes up the experiment in one tool, then has to go log the materials they used in another. Some people do this religiously. But most don't - it's a separate step in a separate application - or worse, spreadsheet - and on a busy day it's the first thing that gets forgotten. And if the reagents and samples that went into an experiment don’t get recorded, your research reproducibility takes a serious hit. That’s just how it is.
Now imagine the same workflow in a platform where the laboratory notebook software and the inventory system are the same tool. The researcher documents their experiment, and as part of that process, they link the reagents and samples they used. There's no extra step in a different application - it's just part of writing up the experiment. Inventory updates happen naturally because they're embedded in the research workflow.
That connection goes both ways, which is where it gets really powerful. Pull up any notebook entry and you can see exactly which materials went into it. Pull up any item in your inventory and you can see every experiment it's been part of. When you need to track sample usage across a project, or trace a problematic result back to a specific reagent lot, or demonstrate full material traceability for an audit, the information is already there. Nobody has to reconstruct it after the fact.
IGOR was built around this exact idea. The electronic lab notebook and the lab inventory management system aren't separate modules bolted together - they're designed as one integrated platform. Your experiment entries, inventory, SOPs, and project documentation all live in the same place and connect to each other without anyone having to manually maintain those links. Once you've used it for a while, the idea of going back to separate systems feels absurd.
The problems that keep coming up (and what actually fixes them)
The same inventory headaches show up in almost every lab I've worked in or talked to people about. They're not complex problems. They're just stubborn, and they compound as teams and inventory grow.
Expired stock that nobody catches.
This one is painfully common. A lab orders a reagent, uses some of it, and the remainder gets pushed to the back of a shelf or freezer and forgotten. Months later, someone finds it - expired, wasted, and now they need to reorder. In labs with large inventories spread across multiple storage locations, this happens a lot. The bigger the inventory, the worse the problem gets.
The fix is visibility. If your team can see what's in stock, where it's stored, and when it expires - all from one screen - then reagents stop falling through the cracks. A good lab inventory management system gives you that without asking anyone to maintain yet another spreadsheet.
Duplicate ordering.
We've all been there. You need a specific antibody, you check the shared spreadsheet, it's not listed, so you order a new one. Two weeks later somebody finds two unopened vials in a freezer across the hall that were never logged.
Or the opposite happens: someone assumes stock is available based on the spreadsheet, plans an experiment around it, and discovers at the last minute that it was used up weeks ago.
It keeps happening because spreadsheet-based tracking only works if everyone updates it religiously. And in a busy lab, they won't. Especially if only one user can update the sheet at any given time. The data is outdated almost as soon as someone enters it.
Once you have structured inventory repositories with consistent naming and searchable storage maps, this kind of thing stops happening. You search, you find it (or confirm it's actually not there), and you move on.
Running out of critical materials mid-experiment.
Every researcher has a story about this. You're mid-experiment, go to the fridge to get out a reagent, and… it's gone. Somebody used the last of it and didn't tell anyone. Or the order was placed too late and shipping took longer than expected. Either way, the experiment stalls and you lose days, or worse, you have to throw out the experiment because you can’t complete it as planned, thus wasting the time and materials already used.
This is a tracking problem. The only way around this is knowing exactly what you have in stock, where it is stored, and how fast you're going through materials before you actually run out. That takes real-time visibility and usage data.
Overstocking and budget waste.
Without actual usage data, most labs order based on gut feeling or habit. Someone orders the same quantity they ordered last time, regardless of whether consumption has changed. Or they order extra "just in case" because running out mid-experiment is worse than having too much. The result is money tied up in stock that sits unused for months, takes up storage space, and sometimes expires before anyone touches it.
The better approach is ordering based on real consumption history. When your inventory system tracks what gets used and how quickly, purchasing decisions stop being guesswork. You can see actual usage patterns and order accordingly.
Inability to trace materials back to experiments.
An auditor asks which reagent lot was used in a particular set of experiments. A collaborator wants to know the passage number of the cells you used in the data you're sharing. Your own team needs to troubleshoot a result and suspects a bad batch of buffer. If your inventory system and your notebook aren't connected, answering these questions means digging through records in multiple places and hoping the information was captured somewhere. When they're integrated, the answer is only a few clicks away.
Loss of institutional knowledge when people leave.
The postdoc who knew where everything was and kept the freezer organized finishes their contract and leaves for a faculty position across the country. Their knowledge of where things are, where to purchase a replacement when stocks run low, and which samples are critical goes with them. If that knowledge only existed in their head (or in a personal spreadsheet on their laptop), your lab is not only starting from scratch, but you’re looking at a period of serious disruption. A centralized laboratory inventory system retains that information regardless of who comes and goes.
What to look for in a lab inventory management system
Not all inventory systems are created equal, and "lab inventory management system" has become one of those terms that vendors apply to everything from a glorified spreadsheet app to a full enterprise LIMS. If you're evaluating options, here's what actually matters in practice.
Integration with experiment documentation.
This is the big one, and many available systems don’t do this, or don’t do this well. If your inventory system doesn't connect to where your experiments are documented, you're going to end up with fragmented data no matter how good the tool is on its own. The most effective setup is a platform where the ELN and inventory management are part of the same system - not separate products that "integrate" through an API you'll never get around to setting up or maintain.
Customizable repositories.
Every lab has different types of materials and samples and needs to track different metadata for their workflows and documentation needs. Your antibody inventory needs different fields than your primer inventory, which needs different fields than your cell line collection. The system should let you define the structure for each type without requiring coding skills or vendor involvement.
Physical storage mapping.
Knowing that you have something is only half the battle. Knowing exactly where it is - which room, which freezer, which shelf, which box, which position - is what actually saves your team time. Interactive storage maps that reflect your real physical layout are worth more than any amount of clever search functionality.
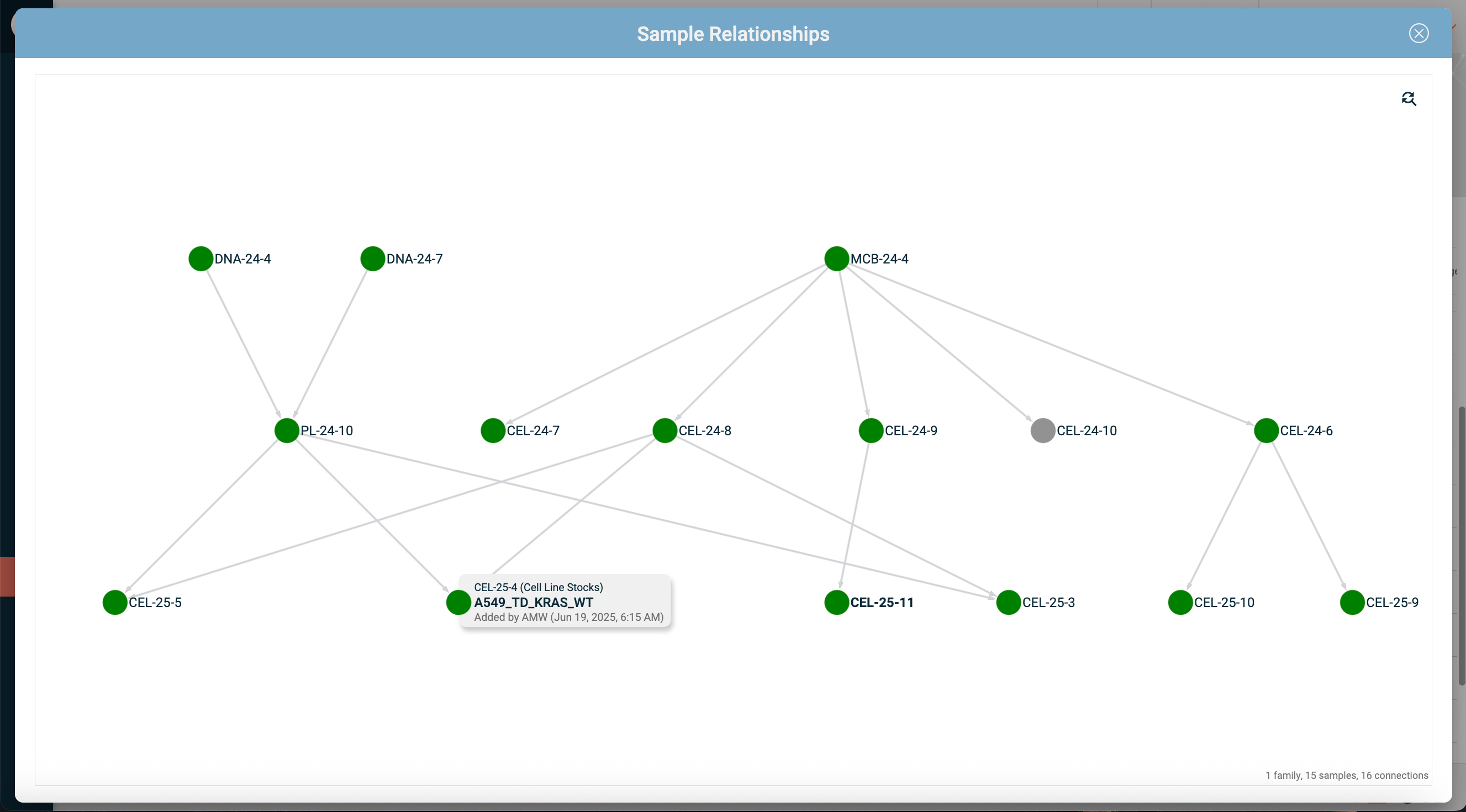
Sample relationship tracking.
In many labs, samples aren't independent entities. They have parents, children, aliquots, and derivatives. A good sample inventory management tool lets you see these relationships visually, so you can trace lineage and understand how your samples are connected to each other, and across experiments.
Audit trails and compliance support.
Labs working under GLP, GMP, or similar regulatory frameworks need inventory records that are traceable and can't be tampered with. That means automatic logging of every change and secure timestamps so you can always see what was modified and by whom. The digital signature and approval workflows that GxP requires are more relevant to your ELN entries and SOPs than to day-to-day inventory work, but having everything on the same platform means your compliance infrastructure is consistent across the board. A cloud based LIMS with audit trails built in from the start is far more practical than trying to bolt compliance onto a tool that wasn't designed for it.
Low friction for daily use.
This is arguably the most important criterion, and the one that's hardest to evaluate from a product demo. The system has to be easy enough that researchers will actually use it as part of their daily workflow. If it adds significant overhead, people will find ways to work around it, and your data will end up just as unreliable as it was with spreadsheets. The best inventory tools are the ones where tracking happens as a natural byproduct of documenting your work. When you're evaluating options, ask about customization: can your scientists or lab managers handle it themselves through a point-and-click interface, or do you need coding skills or vendor support? That's usually a telling indicator. And it's always worth asking for a trial so you can test some basic workflows yourself before committing.
The cloud vs. on-premise question
Traditional LIMS software was almost exclusively on-premise: installed on local servers, maintained by local IT, backed up locally. For large organizations with dedicated informatics teams, this can still make sense. For most research labs, it doesn't.
A cloud based LIMS removes the IT overhead entirely. The vendor handles hosting, security, backups, and updates. Your team accesses the system through a browser from any location. Data is backed up automatically to redundant servers, which is considerably more secure and reliable than most labs' local backup arrangements (if they have any at all).
Cloud also makes a huge difference for multi-site collaboration. If your team works across multiple locations - different buildings, different cities, different countries everyone accesses the same system with the same data. There's no syncing, no local copies getting out of date, no VPN headaches. One system, one source of truth.
The security question comes up a lot. People worry about putting research data in the cloud, and it's understandable: "the cloud" is a non-tangible entity, and having your data stored on a server down the corridor feels more secure because you can physically see it. It's a fair concern, but in practice, your local setup is unlikely to match the security and reliability of the world's leading cloud infrastructure providers like Amazon Web Services (AWS) or Microsoft Azure. And nearly all cloud based LIMS, ELN, and lab inventory system vendors these days run on infrastructure from one of those providers. In reality, a well-run cloud platform with enterprise-grade encryption, automated backups, and proper access controls is significantly more secure than a server sitting in a room down the hall, which is still how some labs operate.
Getting your team to actually use it
This is where most lab inventory initiatives fail. Not in choosing the tool, but in getting adoption. The best laboratory inventory system in the world is useless if your researchers treat it as optional.
A few things help. First, the tool has to be genuinely easy to use. Not "easy after a three-day training session" - actually intuitive on the first day. If someone new to the lab can't figure out how to log a sample or find a reagent within a few minutes of sitting down with it, it's too complicated for a research environment.
Second, the inventory tracking has to be part of the existing workflow, not something separate. This is why the ELN integration matters so much. If tracking materials is just part of documenting an experiment, not an additional step in a different application, compliance with the system becomes almost automatic.
Third, the value has to be immediately obvious to the people using it, not just to management. When a researcher can find what they need in seconds instead of wandering the building, when they can see exactly what's in stock before planning an experiment, when they can trace the history of a sample without asking three colleagues - that's when the tool sells itself.
Fourth, and this is something many labs overlook: the system needs to be flexible enough that individual teams or departments can configure it to match how they actually work, without being so open-ended that everyone sets it up differently. IGOR handles this through independent team workspaces: each group has the option to configure their own inventory repositories, templates, and workflows, but the underlying platform is consistent and data or repositories can be shared across team workspaces when needed.
Making the transition without bringing research to a halt
This is what keeps most labs from pulling the trigger on a proper inventory system. The mental picture is daunting: you'd have to stop all research, go through every freezer and cabinet, log thousands of items, and only then could you actually start using the tool. That could take weeks, and nobody - nobody - has that kind of time to spare.
And honestly, that's the wrong approach anyway.
The approach that actually works is gradual. Start by logging everything new as it comes in. Every reagent that arrives, every sample that gets created - from this point forward, it goes into the system. That's the easy part, because it doesn't require anyone to go back and deal with the existing mess. It just means changing the habit going forward.
For stuff that's already in the lab, you chip away at it over time. Have each person log the materials they pull out for their experiments as they go. Someone grabs an antibody from the minus-20 freezer? Takes them thirty seconds to add it to the system before they start their staining. Over the course of a few weeks, the most frequently used items will naturally get captured first, which is exactly the right priority.
For the less frequently used stuff - the boxes in the back of the minus-80, the shelf of old buffers in the cold room - set a low-pressure target. Ask people to tackle one sample box every two weeks. Tell people to log a few items off the shelf in the corner while they're waiting on a five-minute centrifuge spin. Or go through a section of the under-bench fridge during a fifteen-minute incubation. Nobody needs to set aside dedicated time for this. It happens in the incubation times that every lab day is full of.
One trick that works really well: grab a pack of small round colored stickers from the dollar store and pass them around the lab. Whenever someone logs an item into the system, they stick a colored dot on it. Next person who opens that freezer drawer can see at a glance what's been captured and what hasn't. This prevents items from being logged twice, avoids confusion, and there's something oddly satisfying about watching the dots gradually take over your storage spaces.
Within a couple of months, without anyone having to take a single day off from research, you'll have a working inventory that covers the vast majority of what your lab actually uses. The obscure reagents and old samples that nobody touches will get logged over time, or you'll discover during the process that half of them are expired and can be tossed out anyway. That cleanup is a bonus.
The key insight is this: you don't need a perfect inventory to start getting value from a lab inventory management system. You just need to start. The system gets more useful with every item that goes into it, and the transition happens alongside your research rather than instead of it.
The real cost of not having a system
Labs that put off implementing proper inventory management tend to underestimate what it's costing them. The expenses aren't dramatic or visible - they're a slow leak. A few hundred dollars in expired reagents here. A few hours of wasted researcher time there. A duplicate order. An experiment delayed because materials weren't available. A poorly documented experiment that comes back to haunt you during an audit.
Add it all up over a year and you're looking at thousands of dollars in wasted materials, lost productivity, and a growing pile of institutional knowledge that's trapped in data silos and gets lost over time.
The labs that have their act together and actually run smoothly aren't doing anything magic. They just got the basics right and their team bought in.
That's not a high bar. But it does require getting the foundation right.

FAQ
What's the difference between a LIMS and an ELN?
The two are closely related but serve different roles. A LIMS (Laboratory Information Management System) manages the operational side of a lab: sample tracking, inventory, storage logistics, sample lineage and relationships, workflow management, and compliance documentation. An ELN (Electronic Lab Notebook) is your scientific record, where experiments are documented, protocols managed, and results captured along with any associated data files and images. They basically replace the traditional paper lab notebooks.
Traditionally, ELN and LIMS were separate systems, and a lot of labs still run them that way. The problem is that experiments and materials are deeply intertwined - every experiment uses specific samples and reagents, and every sample has a history of experiments it's been part of. When your LIMS and ELN are separate systems, somebody has to manually bridge that gap. Which is why there's been a clear shift toward platforms that bring both together, though the depth and quality of that integration varies a lot between vendors.
For a more detailed breakdown of how LIMS, ELN, and SDMS compare and how to figure out which one your lab actually needs, we wrote a separate guide on that: “LIMS vs ELN vs SDMS: What Your Lab Actually Needs“.
Do I really need a dedicated lab inventory management system, or can I keep using spreadsheets?
The problem isn't really about discipline; people skip updating any system when they're busy, whether it's a spreadsheet or a LIMS. The difference is that a well-designed inventory system builds the tracking into the workflow. When you document an experiment and link the materials you used, the inventory updates as a byproduct of work you were going to do anyway. A spreadsheet is always a separate task you have to remember to do on top of everything else. That's why spreadsheet data goes stale so much faster. And that's before you even get into the other problems - inconsistent naming conventions, no way to see who changed what and when, no connection between your materials and your experiments. Once your team gets beyond four or five people, a spreadsheet just isn't a viable inventory system anymore.
What should a cloud based LIMS include?
You want structured inventory repositories that you can customize to your materials, storage mapping that reflects your actual physical layout, sample relationship tracking, audit trails, access controls, and encrypted cloud storage with proper backups. It's also worth checking how easy the system is to configure: can your scientists set up and adjust repositories, templates, and workflows themselves, or do you need to go through the vendor every time something changes?
And honestly, the most important thing is that it connects to your experiment documentation. A standalone inventory tool that doesn't talk to your ELN is going to leave you with the same fragmented data problem you're trying to solve.
Do I need to transfer my entire inventory before I can start using the system?
Definitely not, and this is the misconception that stops most labs from ever getting started. Just begin with new materials coming in and let the existing stuff get captured gradually as people encounter it. You don't need a perfect inventory to start seeing value; the system gets better with every item that goes in. If you wait until every single thing is catalogued before you flip the switch, you'll be waiting forever.